Eigentlich ist es ein altes Thema, aber wie ich feststellen musste, wird es immer noch sehr kontrovers diskutiert. Es geht um die paginierten Seiten, die vor allem in Shops entstehen, wenn eine Kategorie viele Artikel enthält und die Darstellung vielleicht noch durch die Anzahl dargestellter Artikel pro Seite und durch verschiedene Filter beeinflusst wird. Solche Seiten drehen sich alle um dasselbe Thema, die URLs sind sich verdammt ähnlich aber die Inhalte sind unterschiedlich. Und es kann sehr viele davon für jede Kategorie geben.
Crawling und Indexierung – die Herausforderung
Die Problematik, mit der wir es hier zu tun haben, ist vielsichtig:
- Die Seiten müssen gecrawlt werden – Jede Seite hat eine begrenzte Crawlkapazität. Große Auftritte haben sicherlich ein höheres Crawlbudget als kleine Webseiten, aber auch deren Kontingent ist beschränkt.
- Google muss priorisieren welche von den vielen Seiten, die letztendlich alle zu den Artikeln derselben Kategorie führen, in den Suchergebnissen angezeigt wird.
- Die Kategorieseiten sind eigentlich nur Nebenschauplatz – das wichtige sind die Artikel die hier verlinkt sind. Die müssen unbedingt in den Index.
Wir wissen, dass es ungünstig ist zu viele gefilterte Inhalte oder Suchergebnisse im Auftritt zu verlinken. Paginierte Seiten sind ja im Grunde auch gefilterte Inhalte – Artikel 1-10 von 250 aus der Kategorie „Holzbohrer“. Daher wurde es immer vermieden zu viele dieser URLs zu erzeugen und in den Index zu schicken. Man hat also die erste Seite einer Kategorie so behandelt, dass sichergestellt war, das nur sie von Google indexiert wurde.
Welche Techniken können bei der Paginierung von Seiten verwendet werden?
Um das Crawling und die Indexierung einer Seitenserie zu beeinflussen, können die folgenden Techniken eingesetzt werden:
- Canonical Tag: Man setzt auf allen Folgeseiten einen Canonical Tag zur ersten Kategorieseite. Der Canonical Tag ist für die Suchmaschine nur eine Empfehlung, kein HTML-Regel. Da alle Folgeseiten sich inhaltlich von der canonischen Seite unterscheiden, kann es passieren, dass Google den Canonical Tag ignoriert und doch die gesamte Serie in den Index aufnimmt. Außerdem wird dadurch der Linkfluss auf die erste Seite umgeleitet. Die Artikel auf den Unterseiten erhalten dadurch keine interne Linkpower mehr.
- Canonical Tag auf eine Catch-All Seite: Mit Catch-All ist eine Seite gemeint, auf der alle Artikel vorhanden sind. Dadurch wird die Klicktiefe sehr niedrig – die Suchmaschine muss nicht erst 100 paginierte Seiten durchblättern – was für den Crawlvorgang sehr von Vorteil ist. Allerdings können Kategorien mit sehr vielen Artikeln so lang werden, dass Sie von der Suchmaschine gar nicht vollständig erfasst werden können. Zu berücksichtigen ist neben der Textmenge (wohl am wenigsten) auch die Datenmenge der vorhandenen Bilder und vor allem die mitunter enorm hohe Zahl von Links.
Desweiteren: die canonisierte Seite ist meist gar nicht auf natürlichem Wege für den User erreichbar, sondern nur über den entsprechenden Tag für die Suchmaschine. Das dürfte diese Seite ebenfalls für die Suchmaschine fragwürdig machen. - Noindex/Follow: Mit dem Metatag robots wird der Suchmaschine die Anweisung gegeben eine Seite nicht zu indexieren, den vorhanden Links aber weiterhin zu folgen. Anders als der Canonical Tag ist der Metatag eine Anweisung an den Bot, keine Empfehlung. Der Linkfluss ist nicht unterbrochen und erreicht weiterhin die verlinkten Artikel auf den Unterseiten.
Long Term Nofollow – John Müller öffnet ein Fass
Am 28.12.2017 hat Barry Schwartz in seinem Artikel (https://www.seroundtable.com/google-long-term-noindex-follow-24990.html) einen ganz neuen Aspekt in die Runde geworfen: Longterm Noindex. Googles Sprachrohr zur SEO-Gemeinde John Müller hat in einem Webmaster Video erwähnt, dass Google mit der Zeit aus einer noindex/follow directive ein noindex/nofollow machen würde. Er erklärte es damit, dass Google Seiten die auf noindex stehen seltener oder nach einer gewissen Zeit gar nicht mehr crawlen würde. Wenn eine Seite gar nicht mehr gecrawlt wird, werden auch die Link auf ihr nicht mehr gesehen, egal ob follow oder nofollow. Auf eine spätere Rückfrage nach dem Zeitraum wann das passieren könnte antwortete John Müller: Das kommt drauf an. Aber das habt ihr euch bestimmt schon gedacht.
John Müllers Erklärung klingt logisch, oder? Auf den ersten Blick ja – auch eine weitere Recherche in der SEO-Szene zeigt, dass viele Abhandlungen zu dem Thema verfasst wurden (https://audisto.com/help/crawler/features/isolation/). Alle empfehlen, zu meinem Erstaunen, die Paginierten Seiten alle auf index/follow stehen zu lassen. Nur die erste Seite soll einen Kategorietext enthalten, um Duplicate Content zu vermeiden. Auf keinen Fall soll man einen Canonical Tag verwenden, damit keine Linkkraft verloren geht. Auch das klingt logisch und konsequent.
Dünner Content vs. Linkjuice
Und trotzdem bereitet es mir Kopping (Kölsch für Migräne). Wir wollen doch vermeiden, dass „dünner Content“ in den Google Index gerät. Ich würde die fünfzigste Kategorieunterseite durchaus als dünnen Content bezeichnen.
Ich habe dieses Thema in einer Facebookgruppe aufgegriffen und war sehr erfreut darüber, dass es so heiß diskutiert wurde. Es konnten zwei Lager ausgemacht werden. Die einen folgen Googles Ausführungen und gehen davon aus, dass ein solches Long Term Nofollow irgendwann auch bei ihnen greifen könnte.
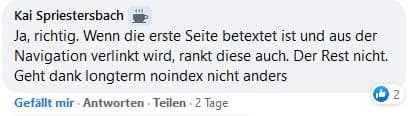
Die anderen orientieren sich an dem, was sie täglich beobachten. Thomas Wagner ist ein heftiger Verfechter dieser Ansicht:
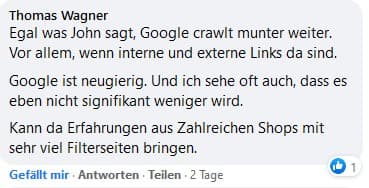
Auch Jens Fauldrath steht John Müllers Aussage sehr kritisch gegenüber:
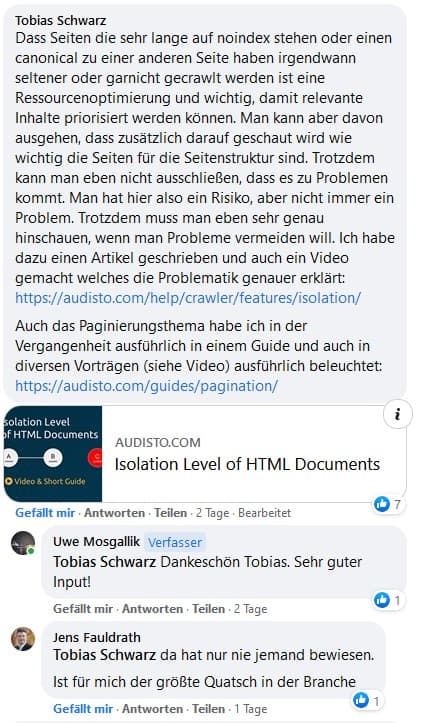
Noindex/Follow != Noindex/Nofollow
Also steckt in der Aussage „Google macht aus Noindex/Follow mit der Zeit ein Noindex/Nofollow“ doch sehr viel graue Theorie. Klar – Google optimiert den Crawlvorgang – bei großen (wirklich großen) Shops ist das auch notwendig. Wann und in welchem Umfang da etwas optimiert wird, ist unklar.
Ich kann mir nicht vorstellen, dass Google sich über einen HTML-Standard hinwegsetzt, den sie selbst mehrmals empfohlen haben. Andererseits: Google setzt sich allerdings auch schon mal über Regeln in der robots.txt hinweg, wenn sie der Meinung sind, das URLs die dort geblockt werden wichtig sind.
Am Schluss bleibt die Beobachtung der täglichen Praxis: Google ist gierig – wer mag das bestreiten? Nicht selten wurden Seiten indexiert die noch Baustellen waren, bei denen der Webdesigner lediglich vergessen hat, ein Noindex einzufügen. Im Googleindex tauchen Seiten auf, die man als Seitenbetreiber selbst noch nicht kannte – weil man noch nie einen eigenen Crawler (Screaming Frog) über die Seiten geschickt hat.
Am Ende gilt, was für so viele Bereiche im SEO gilt: Beobachten, Forschen, Hinterfragen und weiter Beobachten. Nur so bekommt man ein Gefühl für das Verhalten der Suchmaschine auf der eigenen Seite. Und wer kann, sollte genauer hinschauen: Logfile-Analysen – welche Seiten besucht der Bot tatsächlich?
Uwe Mosgallik
Wolfrathshausen, 18.06.2021